Survey of Framework-based Optimization for Federated Learning
⚠ 转载请注明出处:Maintainer: MinelHuang,更新日期:Dec.21 2021

本作品由 MinelHuang 采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 进行许可,在进行使用或分享前请查看权限要求。若发现侵权行为,会采取法律手段维护作者正当合法权益,谢谢配合。
目录
Section 1. 前言:介绍近年federtaed learning system的场景、问题、挑战。
Section 2. GAIA:与distributed infrastructure层面上内存管理,其应用场景为interactive graph computing。
Section 3. Scaling FL System:种为横向联邦学习设计的大规模FL架构。
Section 4. ParSync:一种分布式的资源分配框架,使用partitioned synchronization方法降低了由contention on high-quality resources和staleness of local states带来的scheduling latency。
1. 前言
2. GAIA
参考资料:GAIA: A System for Interactive Analysis on Distributed Graphs Using a High-Level Language. NSDI 2021
场景和Problems
Gaia的应用场景为,在大型集群中对graph data进行迭代式分析。首先简单介绍一下什么是Graph data。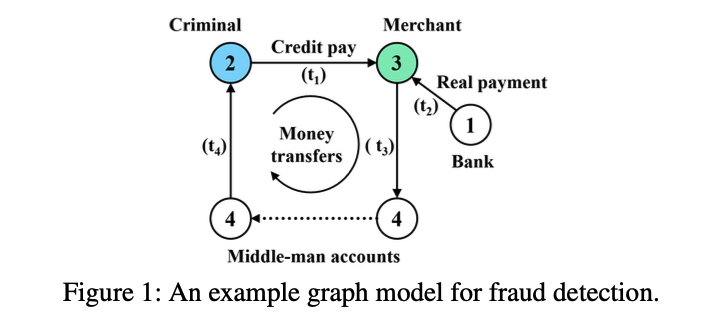
Figure 1便是一个典型的graph data,其描述的是一个罪犯的现金流,例如在t1时,罪犯购买了一个网络商品,t2时银行将钱打给了3号商户。而后在t3时商户将这笔钱又打给了中间人账户,通过一系列中间人,最后再将这笔钱打回罪犯手中(t4)。Graph data analyze便是通过这样一个图数据,分析出是否有洗钱的嫌疑。通常,graph data由点和边组成,点代表着一个实体,边代表实体间的关系,在social networks,commerce transaction,online payments等领域存有大量的graph data。一份图数据可能包含billions of vertices,hundreds of billions to trillions of edges,所以一般需要在一个large cluster上进行处理。Gaia的应用场景是,对于这样一种大规模的图数据,用户会对其进行interactive query analyze,例如提交一个查询query以寻找某个顶点是否存在。故如何低时延的反馈是用户对cluster的需求。Gaia的场景可以概括为:scaling graph data,big cluster,interactive queries and low latency
那么先前的Graph data engines存在哪些问题呢?其一是Programming Model单一,例如Naiad,仅能scaling一些特定的图算法。作为一个distributed framework而言,其program接口没办法满足那些没有distributed computing知识的人。其二是memory management问题,过去的系统主要是基于bulk synchronous parallel (BSP)系统,即计算是迭代式的,每次迭代的运算是相同的。但是BSP系统并不适合interactive graph queries,因为interactive queries过程中通常需要维护大量的app states,这种states可能会随迭代指数倍增长,从而导致memory crisis;在interactive queries场景下,会出现多个queries共享有限内存的情况,当其为了提高效率能cache一部分input graph时,很有可能出现memory crash。
内容概述
此文章中提出Gremlin,其提供了high-level的编程框架。用户提交Gremlin queries,GAIA系统将使用Scope Abstraction描述一个query中的data dependencies,这允许使用dataflow来描述Gremlin traversal,最终达到高效的parallel execution。为了防止memory crash,GAIA在runtime中优化了parallel graph traversal。GAIA的系统框架如下图所示: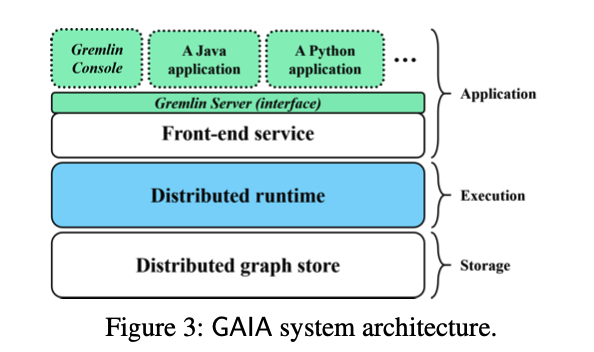
3. Scaling FL System
参考资料:Towards Federated Learning at Scale: System Design. MLSys 2019
此文章提出了一种应用于大规模横向联邦学习的框架,基于TensorFlow开发,同时也是现阶段横向联邦学习的主要应用系统。本章将简单描述此框架。
Protocol
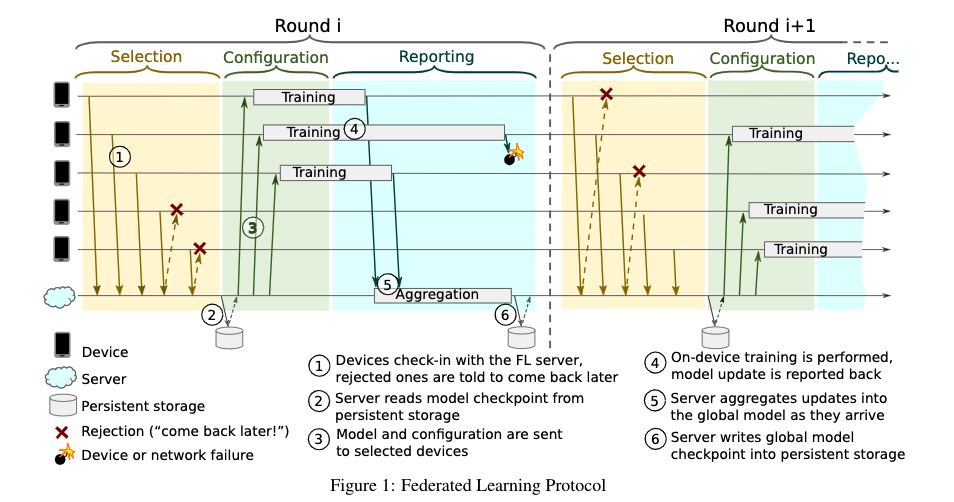
上图是该系统的成员和流程描述图。在此系统中,参与方被称为devices,所有的参与方在本地通过本地数据计算updates,而后上传给centric server。Centric server使用updates更新全局模型,再下发给各个devices,一次迭代结束。
这里首先介绍下该系统中的术语,在Devices上运行的任务称为FL Tasks,在一次迭代中的所有参与devices的规模称为FL population。Server每次迭代会选择此次迭代的FL population,并下发FL plan(一个TensorFlow Graph,用于指导device如何完成FL Tasks)。一次迭代称为round,一旦round被建立,server会给每个参与方发送当前的global model parameters,和FL checkpoint。在同步了术语之后,本章将描述一个round中会有哪些具体的阶段(Phases)。
Phases
Selection: 对应途中黄色部分。Devices向server汇报自身的存在,而后server根据certain goals like the optimal number of participating devices选择合适的参与方。Configuration: 根据aggregation mechanism,配置devices,而后发送FL checkpoint和global model。
Reporting: Server等待devices上传updates。当收到了updates,server使用Federated Averaging方法聚合所有的updates,并更新global model。
在上述过程中包含两个问题,一是如何设置每一次的FL populations,而是在report阶段如何设置recieve time window。在该框架中,提供了Pace Steering阶段,用于Server在round开始前,通过某种算法设置这两个变量以达到某种goal。
Device
本章将描述Device的计算框架。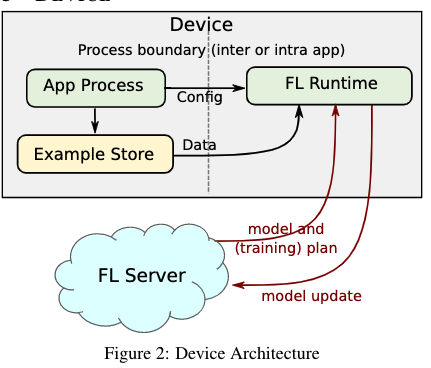
Device中的软件架构如上图。Device需要维护一个example store,例如SQLite database,用于存储本地用于训练或evaluation的数据。在Phase章节中描述的FL训练过程的实现是FL Runtime。
Server
本章描述Server的框架。在横向联邦学习场景中,Server接受到的updates的规模可能是KB到几十MB级别的,每次参与训练的devices数量在几十到hundreds of millions,所以在一次训练时,Server接受到的信息是高度可变的。为了应对这种可变性,通常使用Actor-based系统。Actor可以对接受到的message作出反应,允许创建新的actor和task,下面来介绍Server是如何使用actor承载updates并完成training的。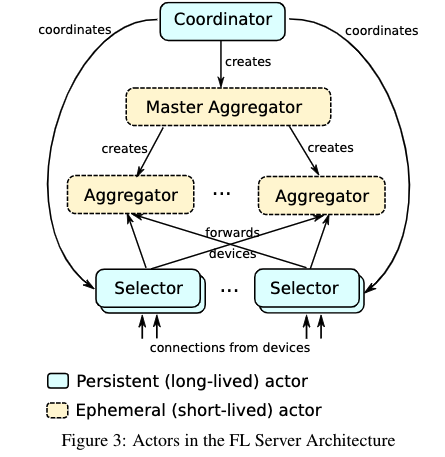
Coordinator是framework中的top-level actor,每一个coordinator与一个FL population相对应。而后Coordinator将该population告知selector,开始一次round。
Selectors负责接收device connections,它们周期性的接受来自Coordinator的FL population信息,而后在本地决策选择哪些devices用于此轮训练并接受updates。当收到updates后,Selector会将updates传递给Aggregators。
Master Aggregators负责管理每个FL task,在runtime中,其动态决定Aggregator的数量。
4. ParSync
参考资料:Scaling Large Production Clusters with Partitioned Synchronization. 2021. ATC
场景和Problems
该论文的场景为对大型集群上运行的billions of tasks进行资源分配,scheduler需要对诸如scheduling efficiency, scheduling quality, resource utilization, fairness and priority等做复杂的取舍。这样以来,scheduler会产生很大的延迟,那么对于大部分short-jobs而言是不能容忍的。故需要降低scheduler的latency。
传统的集中式资源分配架构如YARN很难应对大规模集群,故在此考虑使用分布式资源分配架构。在distributed scheduler中,例如Omega,最大的问题是如何维护cluster state。在Omega中使用master维护cluster state,其余的local scheduler周期性地拷贝cluster state from master,于是在local scheduler中,会存在stale state问题。第二个问题是,多个scheduler会产生scheduling confilcts,这时需要使用master进行裁决。两个问题都会导致high scheduling latency。
故在此文中,将集群划分为N个部分,每个部分的local scheduler对自身部分持有fresh states,对其他部分持有possible stale states。文章证明了这样的架构明显减少了resource contention,不同的parts之间通过partitioned synchronization (ParSync)实现state交换。